اكتسبت نماذج اللّغة الكبيرة، مثل تشات-GPT، شعبيّة كبيرة خلال العاميْن الماضيين. يتعلّق نجاحها إلى حدٍّ كبير بقدرتها العالية على الإجابة على الأسئلة المعقّدة، في مجال واسع من المواضيع، والرّدّ عليها في محادثة تبدو طبيعيّة.
قد يبدو نجاحهم مفاجئًا بالنّظر إلى طريقة “تفكيرهم”، والّتي تختلف كثيرًا عن الطّريقة الّتي نفكّر بها ونتواصل بها نحن البشر. في الواقع، هناك سؤال واحد فقط يعنيهم: بالنّظر إلى سلسلةٍ من الأحرف أو الكلمات، ما هو الحرف أو الكلمة التّالية الّتي من المتوقّع أن تكون ملائمة بالصّورة الأفضل للتّواصل مع البشر؟ مثلاً، بالنّظر إلى التّسلسل “عاصمة فرنسا هي”، فإنّ النّموذج سوف يتوقّع كلمة “باريس” باعتبارها الاستمرار الأكثر احتمالًا لها. لقد حقّق النّموذج هذه القدرة التّنبّؤيّة بفضل التّدريب المكثّف- التّعرّض لكمّيّة هائلة من النّصوص من أنحاء الإنترنت، وهكذا فقد تعلّم كيف يتعرّف على الكلمات، ويحدّد علاقاتها بالكلمات الأخرى، وأصبح على دراية بقواعد النّحو والصّرف في اللّغة البشريّة.
تبدأ المشكلة عندما يُطرَح عليه سؤال لم يسبق له أن واجهه من قبل. في حالات مثل هذه، قد يقع في فخّ: إمّا اختراع حقائق خاطئة أو كاذبة بشكل واضح، أو إعطاء إجابة بليغة ولكن فارغة من المضمون، أو إلقاء الهراء بكلّ بساطة. لمَ يحدث هذا؟

إنّ الطّريقة الّتي “يفكّر” بها “بوت المحادثة” تختلف كثيرًا عن الطّريقة الّتي نفكّر بها ونتواصل بها نحن البشر مع بعضنا البعض. بوت محادثة يتحدّث | Ikon Images / Liam Bardsley / Science Photo Library
شيء غير وارد
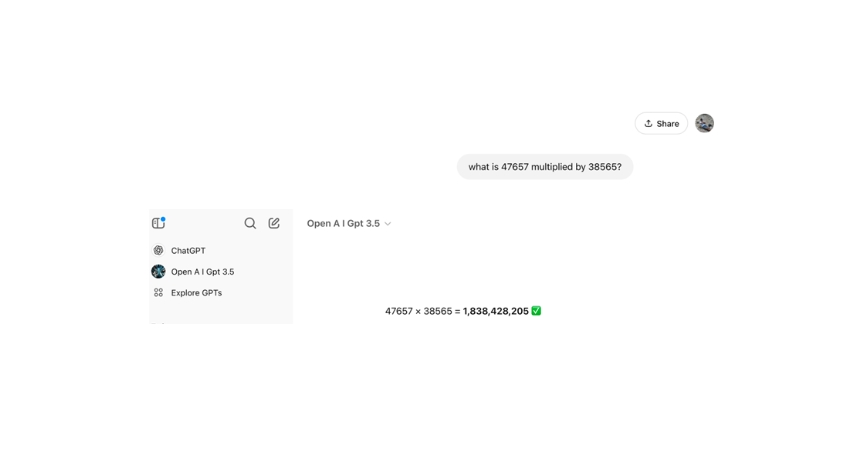
طرحتُ على تشات-GPT سؤالاً في الضّرب يَسهُل على الآلة الحاسبة الجيبيّة حسابه ببساطة شديدة، عن حاصل ضرب عددين صحيحين مكوّنين من خمسة أرقام -ما هو حاصل ضرب 47,657 في 38,565؟ الإجابة الصّحيحة هي 1,837,892,205، لكن كانت إجابة Chat-GPT: 1,838,428,205- رقم يحوي أربعة أرقام غير صحيحة. فما السّبب بالضّبط؟
لهذه الفجوة عدّة أسباب. أوّلًا، لم يرَ النّموذج ما يكفي من الأمثلة لمثل هذه الحسابات. عندما قام الباحثون من معهد ألين للذّكاء الاصطناعيّ بتدريب نموذج لغويّ على قاعدة بيانات لعمليّات ضرب قصيرة، تحسّنت قدرته بشكل كبير ونجح بعد ذلك بشكلٍ جيّد في التّنبّؤ بإجابات لمشاكل مماثلة.
بالإضافة إلى ذلك، فإنّ النّموذج يعتمد على النّصّ ولا يقوم بإجراء حسابات رياضيّة مثل الآلة الحاسبة الجيبيّة. ليس لديه حتّى ذاكرة يمكنه من تخزين النّتائج المؤقّتة فيها. عندما يتلقّى “تشات-GPT” سؤالاً مثل هذا، فإنّه يقرأ الأرقام كأحرف نصّيّة عاديّة، تمامًا مثل الأحرف وعلامات التّرقيم. يُقسِّم النّصّ بأكمله إلى وحدات قصيرة من الكلمات أو أجزاء من الكلمات، والّتي تُسمّى رموزًا (tokens). تُحوّلُ كلّ وحدة من هذه الوحدات، اعتمادًا على السّياق، إلى تعبير رقميّ يُسمّى مُتَّجَهًا (Vector)، وتُجرى بقيّة أعمال المعالجة عليه. حتّى عمليّة الضّرب نفسها تُحوَّل من نصّ إلى متَّجهات. في النّهاية، بعد أعمال معالجة المتَّجهات من أجل التّنبّؤ بالتّركيبة الأكثر احتمالًا، يقوم النّموذج بتحويل المتّجه النّاتج مرّة أخرى إلى نصّ- في هذه الحالة، إلى أرقام.
تشات-GPT يواجه مشكلة في عمليّات الضّرب الطّويل
منزل الحمار الوحشيّ
لغز الحمار الوحشيّ، المعروف أيضًا باسم “لغز آينشتاين” -على الرّغم من أنّه لا علاقة له بألبرت آينشتاين- هو نوع من أنواع التّحدّيات الفكريّة الّتي يتطلّب حلّها تقسيمَها إلى مشاكل فرعيّة واستنتاجات منطقيّة. يبدأ اللّغز بتقديم سلسلة معطيات مثل “البريطانيّ يعيش في المنزل الأحمر”، و”النّرويجيّ يشرب الماء”، و”الرّجل الّذي يعيش في المنزل الأوسط يربّي القطط”. إنّ الموازنة المدروسة لكافّة التّفاصيل معًا سوف توفّر الإجابة على سؤال معيّن- مثلا، “من الّذي يربّي الحمار الوحشيّ؟”
اُستخدمت مشاكل مثل هذه على مرّ السّنين لاختبار مستوى تعقيد الخوارزميّات. هنا أيضًا، تميل “بوتات المحادثة”
إلى مواجهة صعوبة في العثور على حلٍ للّغز، بسبب الجانب الرّياضيّ- المنطقيّ للمشكلة. طالما ظلّت المشكلة بسيطة وتشمل منزلًا واحدًا أو منزلين، فإنّ النّموذج ينجح في حلّها بشكل جيّد جدًّا، ولكن عندما يزداد عدد المنازل ويتعقّد الحلّ، فإنّ النّموذج يفشل.
عندما يحاول شخص ما حلّ مثل هذه المشكلة، فإنّه عادة ما يستخدم الجداول والمخطّطات لمساعدته في تنظيم المعلومات والاستنتاجات الّتي يستخلصها منها، وتوثيقها كتابيًّا. لا يحتوي النّموذج على ذاكرة عمل مثل هذه، ولكلّ كلمة أو مجموعة من الأحرف المكتوبة، يحتفظ بمتَّجه يمثّلها ويتغيّر أثناء عمليّات المعالجة. عندما يقوم النّموذج بتحليل السّؤال، فإنّه يقوم بفحص جميع العلاقات والارتباطات بين كلّ كلمة وجاراتها، ويمثّل هذه البيانات في متّجهها. إذا حاول إكمال الجملة “عاصمة فرنسا هي”، فإنّه يفحص فقط متّجه الكلمة الأخيرة- “هي”. إنّ سياق الكلمة، أي الجملة كاملةً، يكون قد أصبح متجسّدًا في متّجه تلك الكلمة.
لماذا هذا الأمر مهمّ؟ في سلسلة من الرّموز، على الرّغم من أنّ السّياق بأكمله يكون موجودًا في متَّجه (Vector) الكلمة الأخيرة، إلّا أنّه غير موجود بطريقة متوازنة- حيث يكون للمعلومات اللّاحقة وزنًا أكبر من المعلومات الّتي سبقتها. لذلك، فإنّ الرّموز الأولى، على الرّغم من أهمّيّتها الحاسمة في حلّ اللّغز، يتمّ تجاهلها كلّيًّا أو جزئيًّا، ولا يتمّ وزنها بشكل صحيح في الإجابة.

نوع من التّحدّيات التّفكيريّة الّتي يتطلّب حلّها تقسيمًا إلى مشاكل فرعيّة واستنتاجات منطقيّة. اللّغز يسأل من هو الّذي يربّي الحمار الوحشيّ | ليات بيلي، عبر DALL-E
القاسم المشترك
على الرّغم من التّشابه الكبير بين نماذج اللّغة الرّئيسيّة، مثل استخدام تسلسلات الحروف والرّموز، وتحويلها إلى قيم عدديّة (مُتّجهات)، وحساب العلاقة بين الكلمات، إلّا أنّ هناك أيضًا اختلافات جوهريّة بينها. لذلك، فإنّ جزءًا من الشّرح الّذي قدّمته صحيح فيما يتعلّق بكيفيّة عمل “تشات-GPT”؛ إلّا أنّه لا يمثّل بالضّرورة جميع نماذج اللّغة الأخرى.
ومع ذلك، فإنّ هذه الصّعوبات تنطبق على معظم النّماذج. يحاول بعضها التّغلّب على النّسيان باستخدام آليّات تقوم بالحفاظ على أهمّيّة التّسلسلات السّابقة، أو من خلال التّدريب على مجموعة من الأمثلة، حيث يتطلّب حلّ المشكلة فيها استخدام المعلومات الأحدث وأيضًا المعلومات الأقدم. من خلال التّعرّض لعدد كافٍ من الأمثلة، يتعلّم النّموذج كيفيّة التّعامل مع الصّعوبة.
من المتوقّع اليوم أن تستمرّ أدوات الذّكاء الاصطناعيّ الّتي ظهرت في حياتنا خلال العامين الماضيين في التّحسّن واحتلال مكانة مركزيّة ومهيمنة بشكل متزايد في عالمَي الإنترنت والكمبيوتر وفي عمل المجتمع البشريّ. وكما يحدث تقريبًا مع كلّ ثورة تكنولوجيّة كبيرة، هناك أيضًا من يتوقّع أنّ الذّكاء الإصطناعيّ سيحلّ محلّ البشر. في النّهاية، مهما كان شكل صلتها بحياتنا، من المهمّ جدًّا أن نفهم كيفيّة عمل نماذج الذّكاء الاصطناعيّ، والأهمّ من ذلك، ما هي محدوديّتها.


